Um den Flow beherrschbar zu machen, braucht es Transparenz. Und Transparenz entsteht am zuverlässigsten durch Metriken. Allerdings sind Metriken für viele Softwareentwickler ein rotes Tuch. Kein Wunder – schließlich wurden sie in der Vergangenheit oft auf eine Weise eingesetzt, die mehr Schaden angerichtet als geholfen hat.
Dieser Artikel möchte deshalb bewusst einen differenzierten Blick auf das Thema werfen. Denn Metriken sind weder Teufelszeug noch ein Wundermittel. Richtig eingesetzt, helfen sie Teams dabei, Engpässe sichtbar zu machen, bessere Entscheidungen zu treffen und den Flow im System gezielt zu verbessern.
Im ersten Teil dieser Artikelserie wurde beschrieben, wie Softwareentwicklungsteams von Flow-Prinzipien profitieren können und warum es wichtig ist, diesen Flow aktiv zu steuern. Dafür braucht es vor allem Transparenz – Transparenz darüber, wie Arbeit tatsächlich durch das System fließt.
Wie diese Transparenz erreicht werden kann, welche Metriken dabei hilfreich sind und wie diese sinnvoll interpretiert werden sollten, darum geht es in diesem zweiten Teil der Serie.
Metriken – Teufelszeug oder unverzichtbares Hilfsmittel?
Bevor wir uns konkrete Flow-Metriken ansehen, lohnt sich zunächst ein allgemeiner Blick auf den Umgang mit Metriken. Denn viele Entwickler haben ein eher gespaltenes Verhältnis dazu. Ich selbst habe zahlreiche Situationen erlebt, in denen Metriken auf eine ungute Weise eingesetzt wurden.
Grundsätzlich sind Metriken ein wertvolles Hilfsmittel.
Sie helfen dabei:
- Veränderungen sichtbar zu machen,
- Zusammenhänge besser zu verstehen,
- Probleme früher zu erkennen,
- und Verbesserungen empirisch zu bewerten.
Gleichzeitig beeinflusst jedoch jede Metrik auch das Verhalten innerhalb des Systems. Und häufig ist genau diese Verhaltensänderung sogar beabsichtigt. Wenn beispielsweise die Anzahl gemeldeter Bugs gemessen wird, steckt dahinter meist die Hoffnung, dass dadurch die Sensibilität für Qualität steigt und die Anzahl der Fehler sinkt.
Soweit die Theorie.
In der Praxis lässt sich jedoch häufig beobachten, dass Zielmetriken unerwünschte Nebenwirkungen erzeugen. Bugs werden plötzlich „wegdiskutiert“. Probleme werden als neue Feature-Requests klassifiziert. Deployments werden hinausgezögert, um weniger Fehler sichtbar werden zu lassen oder der Prozess zum Melden neuer Fehler wird für die Anwender verkompliziert, so dass dies zu weniger gemeldeten Fehlern führt.
Teams beginnen die Metrik selbst zu optimieren statt das zugrunde liegende System. Genau dieses Phänomen beschreibt übrigens auch Goodhart’s Law:
„When a measure becomes a target, it ceases to be a good measure.“
Sobald Menschen beginnen, eine Kennzahl aktiv zu optimieren, verliert diese häufig ihren ursprünglichen Aussagewert. Das gilt nicht nur für Bugs. Wenn beispielsweise Code Coverage oder die Anzahl von Unit Tests zum Ziel erklärt werden, entstehen zwar oftmals mehr Tests – aber nicht zwangsläufig bessere Qualität. Im schlimmsten Fall erzeugen solche Metriken sogar ein falsches Gefühl von Sicherheit.
Ein weiteres Problem besteht darin, dass Metriken leicht zu lokalen Optimierungen führen. Ein einzelner Bereich verbessert seine Kennzahlen, während das Gesamtsystem dadurch schlechter funktioniert.
Und schließlich gilt: Metriken selbst führen niemals zu Verbesserungen.
Sie helfen lediglich dabei, die richtigen Fragen früher zu stellen. Damit aus Transparenz letztendlich tatsächliche Verbesserungen entstehen, braucht es:
- Zeit,
- Reflexion,
- Ursachenforschung,
- Experimente,
- und die Bereitschaft, das System anzupassen.
Eine Aussage wie:
„Die Anzahl der Bugs ist zu hoch, sie muss sinken“
führt selten zu nachhaltiger Verbesserung. Sie führt meistens nur dazu, dass Zahlen „massiert“ werden.
Metriken als Gesprächsanfang
Genau deshalb sollten Metriken nicht als Kontrollinstrument verstanden werden. Ihr eigentlicher Wert liegt darin, Diskussionen anzustoßen.
Sie helfen Teams dabei:
- Auffälligkeiten sichtbar zu machen,
- Hypothesen zu formulieren,
- systemische Probleme zu erkennen,
- und Verbesserungen empirisch zu überprüfen.
Gute Flow-Metriken fördern damit Lernen. Schlechte Nutzung von Metriken erzeugt dagegen häufig:
- Angst,
- Defensivverhalten,
- Verstecken von Problemen,
- Schönfärberei,
- und lokale Optimierung.
Gerade deshalb ist der kulturelle Umgang mit Metriken mindestens genauso wichtig wie die Metriken selbst.
Empfehlungen für den Umgang mit Metriken
Deshalb hier einige grundlegende Empfehlungen:
- Metriken nicht als Zielvorgaben verwenden, sondern als Informationsquelle.
- Metriken gemeinsam im Team definieren statt „von oben“ vorzugeben.
- Verschiedene Metriken kombinieren, um lokale Optimierung zu vermeiden.
- Nicht einzelne Personen messen, sondern Systeme betrachten.
- Zeit schaffen, um Erkenntnisse tatsächlich in Verbesserungen umzusetzen.
Flow-Metriken
Im Folgenden betrachten wir einige grundlegende Metriken im Zusammenhang mit Flow.
Abbildung 1 – Die wichtigsten Flow-Metriken
Diese sollten selbstverständlich durch weitere Perspektiven ergänzt werden – beispielsweise:
- Qualitätsmetriken,
- Kundenzufriedenheit,
- technische Stabilität,
- oder Outcome-Metriken.
Flow-Metriken beantworten primär die Frage: „Wie bewegt sich Arbeit durch unser System?“
Sie sagen dagegen nicht automatisch etwas darüber aus, ob die entwickelte Software tatsächlich wertvoll ist. Der Fokus dieses Artikels liegt bewusst auf dem Thema Flow, mit expliziter Betonung darauf, dass diese Metriken nur einen Teilaspekt erfolgreicher Softwareentwicklung abdecken.
Ein großer Vorteil der hier vorgestellten Metriken besteht darin, dass sie sich vergleichsweise einfach erheben lassen. Erstaunlicherweise berücksichtigen diese die Größe der Arbeitselemente gar nicht. Oft genügt:
- das Messen von vergangener Zeit,
- und das Zählen von Elementen.
Damit stellt sich schnell eine interessante Frage: Braucht es Aufwandsschätzungen überhaupt zwingend?
Verschiedene Untersuchungen zeigen zumindest, dass schätzfreie Flow-Metriken in vielen Fällen ähnlich gute oder sogar bessere Prognosen ermöglichen als klassische größenbasierte Verfahren. Der Grund dafür liegt vor allem darin, dass stabile Systeme mit geringer Variabilität häufig besser vorhersagbar sind als Systeme mit sehr detaillierten, aber stark schwankenden Schätzungen. Gute Forecasts entstehen daher oft weniger durch immer präzisere Schätzungen.
Sie entstehen vielmehr durch:
- stabileren Flow,
- kleinere Arbeitspakete,
- geringere Variabilität,
- und kürzere Rückkopplungszyklen.
Wer tiefer in dieses Thema einsteigen möchte, findet dazu weitere Gedanken in meinem separaten Artikel zum Thema Aufwandsschätzung.
Cycle Time
Die Cycle Time – auf Deutsch Durchlaufzeit – beschreibt die Zeit, die ein Element benötigt, um unseren Workflow zu durchlaufen. Wie bereits im ersten Teil der Serie beschrieben, hängen die daraus resultierenden Erkenntnisse und die abgeleiiteten Optimierungen stark davon ab, wie Start- und Endpunkt des Workflows definiert wurden.
Es kann sinnvoll sein, verschiedene Cycle Times parallel zu betrachten.
Zum Beispiel:
- vom Start der Entwicklung bis zum Deployment,
- von der Anforderung bis zur Nutzung,
- oder nur für einzelne Teilbereiche wie Implementierung oder Test.
Die Cycle Time wird üblicherweise für jedes einzelne Work Item ermittelt. Eine häufig genutzte Visualisierung ist dabei der sogenannte Cycle Time Scatter Plot.
Daraus lassen sich unter anderem ableiten:
- durchschnittliche Durchlaufzeiten,
- Perzentile,
- Service Level Expectations (SLE),
- und Auffälligkeiten im System.
Product Backlog in die Betrachtung einbeziehen?
In vielen Teams startet die Cycle Time erst mit Beginn der eigentlichen Umsetzung. Das Product Backlog wird häufig bewusst ausgeschlossen. Schließlich verbringen Elemente dort oftmals Wochen oder gar Monate. Aber vielleicht wäre es gerade deshalb spannend, auch diesen Teil des Systems transparent zu machen. Denn aus Sicht von Stakeholdern oder Kunden beginnt die Wartezeit meist nicht erst mit der Entwicklung. Sondern bereits dann, wenn ein Wunsch geäußert wird.
Damit entstehen interessante Fragen:
- Wie lange dauert es tatsächlich vom Wunsch bis zur Nutzung?
- Enthält unser Backlog vielleicht viel mehr Arbeit als realistisch umsetzbar ist?
- Werden dauerhaft mehr Themen angenommen als abgeschlossen?
Ein dauerhaft wachsendes Backlog bedeutet letztlich nichts anderes als dauerhaft steigendes WIP. Genau deshalb kann es sinnvoll sein, auch das Backlog als Teil des Systems zu betrachten. Ebenso lohnt sich die Frage, ob Deployment und tatsächliche Nutzung nicht ebenfalls Teil des Flows sein sollten.
Warum Varianz wichtiger ist als Durchschnittswerte
Besonders spannend ist dabei nicht nur der Durchschnitt. Oft ist die Varianz sogar deutlich interessanter. Warum benötigen manche Elemente wesentlich länger als andere? Gab es Blocker? Waren die Elemente ungewöhnlich groß? Gab es Abhängigkeiten? Wurde während der Bearbeitung häufig Kontext gewechselt? Genau diese Ausreißer liefern häufig die wertvollsten Hinweise auf systemische Probleme.
Je geringer die Varianz in einem System, desto stabiler wird der Flow. Und desto besser werden typischerweise auch Prognosen. Das ist ein wichtiger Unterschied zu klassischen planungsorientierten Ansätzen. Nicht möglichst exakte Detailschätzungen erzeugen Vorhersagbarkeit. Sondern ein stabiles System mit gleichmäßigem Flow.
Flow vs. Auslastung
Traditionelle Systeme versuchen häufig, maximale Auslastung zu erreichen. Die zugrunde liegende Annahme lautet: Wenn alle Personen jederzeit beschäftigt sind, arbeitet das System besonders effizient. Leider führt genau diese Denkweise in komplexer Wissensarbeit häufig zum Gegenteil. Eliyahu M. Goldratt beschreibt diesen Zusammenhang sehr anschaulich in seinem Buch „The Goal“. Hohe Auslastung erzeugt Warteschlangen. Warteschlangen verlängern Wartezeiten. Und längere Wartezeiten verschlechtern den Flow.
Eine vereinfachte Formel beschreibt diesen Zusammenhang:
Wartezeit = Auslastung / (100 % – Auslastung)
Das bedeutet:
- Bei 50 Prozent Auslastung ergibt sich eine Wartezeit von 1.
- Bei 98 Prozent Auslastung steigt die Wartezeit bereits auf 49.
Das zeigt sehr deutlich: Systeme sollten nicht dauerhaft maximal ausgelastet werden. Interessanterweise ist dieses Verhalten Softwareentwicklern oft gar nicht so fremd. Eine CPU, die dauerhaft bei 98 Prozent Auslastung läuft, ist schließlich ebenfalls nicht effizient und erzeugt lange Bearbeitungszeiten und erzeugt ein System, das sich von außen extrem langsam anfühlt. Am Ende werden weniger Operationen ausgeführt als bei einer niedrigeren Auslastung.
Work in Process (WIP)
Die zweite wichtige Flow-Metrik ist WIP – Work in Process bzw. Work in Progress. Dabei wird gezählt, wie viele Elemente sich aktuell im System befinden.
Wichtig ist dabei: Zum WIP zählen auch:
- blockierte Elemente,
- wartende Elemente,
- und Aufgaben, an denen momentan nicht aktiv gearbeitet wird.
Denn auch diese Elemente beeinflussen den Flow. WIP lässt sich sehr gut über die Zeit visualisieren. Dadurch werden Muster sichtbar:
- Staut sich Arbeit regelmäßig an bestimmten Stellen?
- Steigt das WIP in bestimmten Situationen?
- Entstehen Engpässe bei Urlauben oder Abhängigkeiten?
- Gibt es Phasen mit besonders vielen Blockern?
Gerade im Daily Scrum oder ähnlichen Austauschformaten kann ein Blick auf das aktuelle WIP sehr hilfreich sein. Nicht die Frage: „Hat heute jede:r genug Arbeit?“ steht dann im Mittelpunkt. Sondern vielmehr: „Was können wir heute gemeinsam tun, um möglichst viele bereits begonnene Elemente abzuschließen?“ Das verschiebt den Fokus von individueller Auslastung hin zum gemeinsamen Flow.
Work Item Age
Die Cycle Time kann erst nach Abschluss eines Elements ermittelt werden. Damit eignet sie sich gut zur Analyse der Vergangenheit. Das Work Item Age dagegen betrachtet die Gegenwart. Es beschreibt das aktuelle Alter eines noch nicht abgeschlossenen Elements. Damit wird Work Item Aging zu einer Art Frühwarnsystem.
Bereits während der Bearbeitung lässt sich erkennen:
- Welche Elemente ungewöhnlich lange im System sind,
- welche Aufgaben vermutlich die SLE gefährden,
- und wo frühzeitig gegengesteuert werden sollte.
Anstatt Probleme erst nachträglich auszuwerten, werden Risiken bereits sichtbar, bevor SLEs gerissen werde. Dadurch eröffnen sich Handlungsspielräume um noch entsprechend gegenzusteuern. Das macht Work Item Aging zu einer der praktischsten Flow-Metriken im täglichen Arbeiten.
Throughput
Die vierte grundlegende Flow-Metrik ist der Throughput. Der Throughput beschreibt, wie viele Elemente innerhalb einer bestimmten Zeiteinheit abgeschlossen wurden.
Zum Beispiel:
- pro Woche,
- pro Sprint,
- oder pro Monat.
Damit ähnelt der Throughput auf den ersten Blick der bekannten Velocity. Der wesentliche Unterschied besteht jedoch darin, dass Throughput die Größe der Elemente ignoriert. Es werden lediglich abgeschlossene Elemente gezählt. Das mag zunächst problematisch wirken. Interessanterweise entstehen daraus jedoch oft erwünschte Effekte. Die einfachste Möglichkeit, den Throughput zu erhöhen, besteht nämlich darin, Arbeit in kleinere, besser schneidbare Einheiten aufzuteilen.
Wichtig dabei: Kleine Elemente sind kein Selbstzweck. Es geht nicht darum, künstlich möglichst viele Tickets zu erzeugen. Der eigentliche Nutzen kleinerer Arbeitseinheiten liegt vielmehr in:
- schnellerer Rückkopplung,
- früherer Integration,
- geringerem Risiko,
- besserer Vorhersagbarkeit,
- und kürzeren Lernzyklen.
Voraussetzung dafür ist allerdings, dass Arbeit vertikal geschnitten wird. Die Teilaufgaben sollten also möglichst eigenständig nutzbare oder validierbare Ergebnisse liefern.
Blocked Time
Eine weitere interessante Flow-Metrik ist die sogenannte Blocked Time.
Dabei wird betrachtet:
- wie lange Elemente blockiert sind,
- wie häufig Blocker auftreten,
- und welche Arten von Blockern besonders oft vorkommen.
Gerade in komplexen Organisationen entstehen erhebliche Verzögerungen nicht durch die eigentliche Umsetzung.
Sondern durch:
- fehlende Entscheidungen,
- externe Abhängigkeiten,
- Wartezeiten,
- Freigaben,
- oder technische Probleme.
Blocked Time hilft dabei, genau diese systemischen Verzögerungen sichtbar zu machen. Oft liegen hier die größten Hebel für Verbesserungen.
Flusseffizienz
Eine etwas andersartige Metrik ist die sogenannte Flusseffizienz. Dabei wird die aktive Bearbeitungszeit ins Verhältnis zur gesamten Cycle Time gesetzt.
Wenn beispielsweise:
- die eigentliche Bearbeitung eines Fehlers 1 Stunde dauert,
- die gesamte Durchlaufzeit jedoch 99 Stunden beträgt,
liegt die Flusseffizienz bei 1/99.
Die Flusseffizienz macht damit sichtbar, wie groß der Anteil reiner Wartezeit im System ist. Je höher die Flusseffizienz, desto geringer die Wartezeiten. Wichtig dabei: Eine höhere Flusseffizienz entsteht nicht durch maximale Auslastung, sondern typischerweise durch:
- bessere Zusammenarbeit,
- weniger Übergaben,
- geringeres WIP,
- schnellere Entscheidungen,
- und weniger Blocker.
Metriken visualisieren
Flow-Metriken entfalten ihren größten Nutzen häufig dann, wenn sie visualisiert werden. Dabei geht es weniger um Management-Dashboards, sondern vielmehr darum, Muster und Veränderungen im System für das Team sichtbar zu machen.
Cumulative Flow Diagram (CFD)
Ein sehr bekanntes Diagramm im Kontext von Kanban und Flow ist das sogenannte Cumulative Flow Diagram. Dabei wird die Anzahl der Elemente in den einzelnen Phasen des Workflows über die Zeit als gestapelte Fläche dargestellt.
Das CFD eignet sich besonders gut für:
- Trendanalysen,
- das Erkennen von Engpässen,
- und die Beobachtung systemischer Veränderungen.
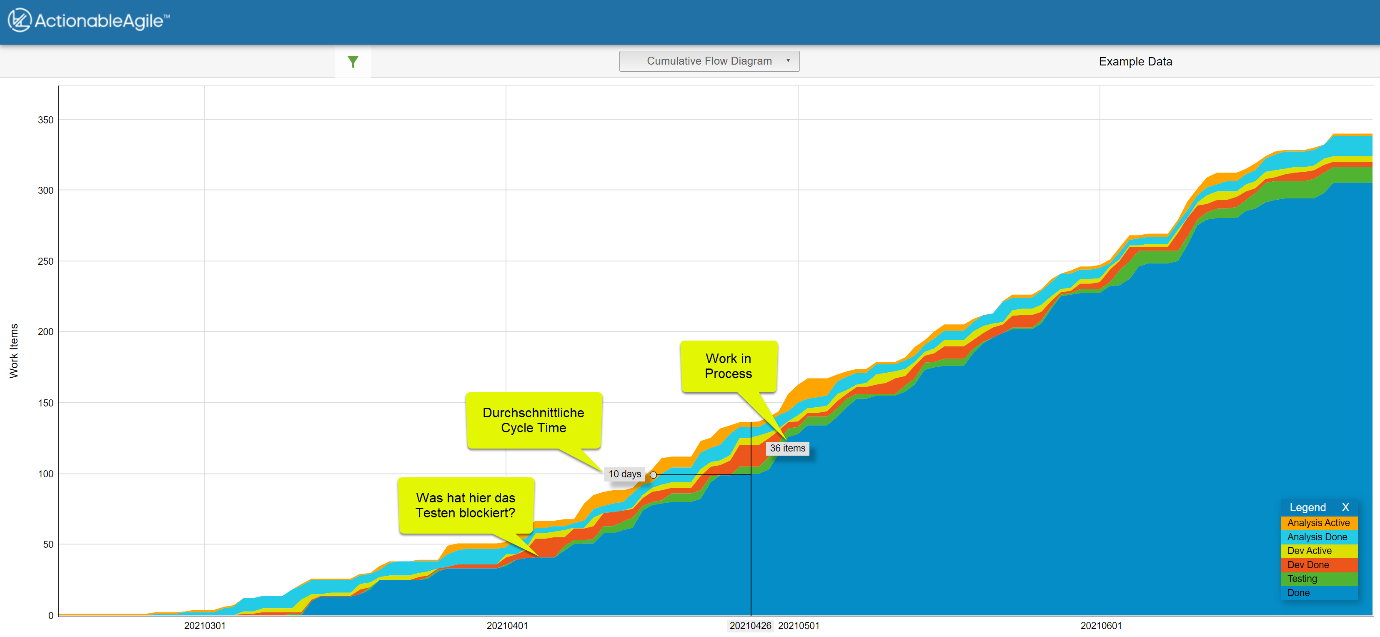
Abbildung 2 – Cumulative Flow Diagram
Cycle Time Scatter Plot (CTS)
Der Cycle Time Scatter Plot bietet einen deutlich detaillierteren Blick auf die Durchlaufzeiten einzelner Elemente. Dabei wird auf der X-Achse das Abschlussdatum und auf der Y-Achse die Cycle Time dargestellt. Blockierte Elemente können zusätzlich farblich hervorgehoben werden.
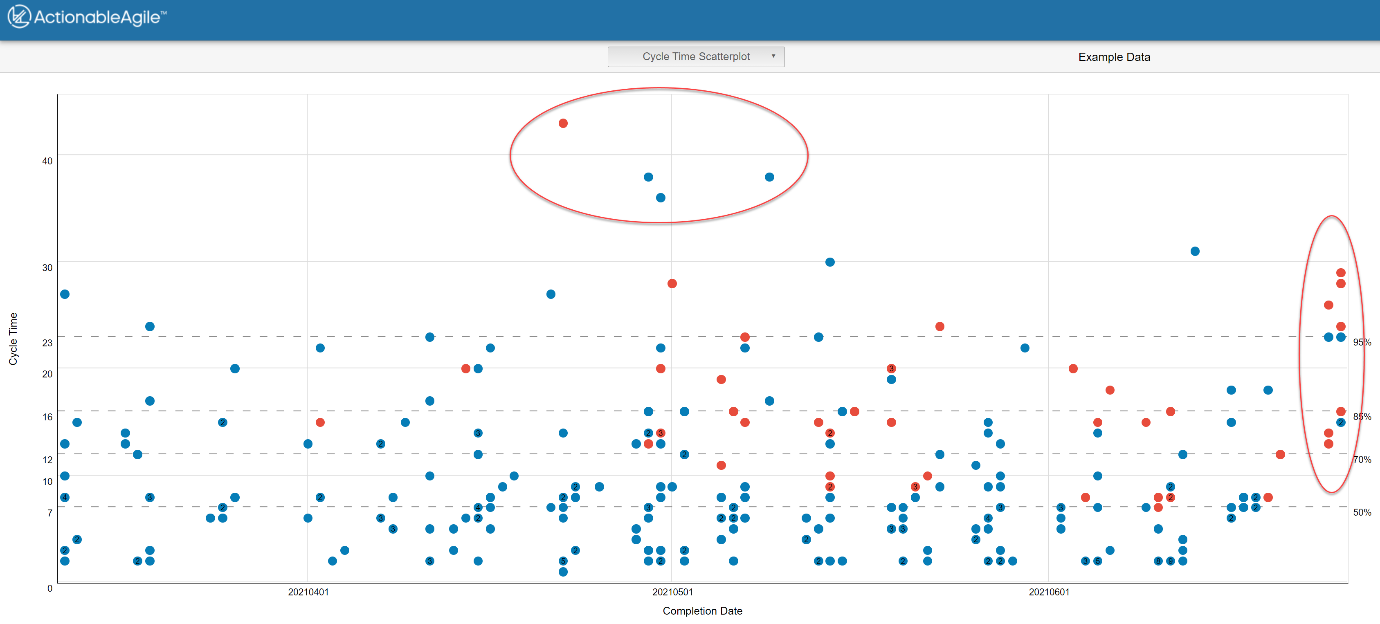
Abbildung 3 – Cycle Time Scatter Plot
Gerade Ausreißer liefern häufig wertvolle Erkenntnisse. Warum waren bestimmte Elemente besonders langsam? Warum häufen sich Blocker in bestimmten Zeiträumen? Welche Veränderungen haben den Flow verbessert?
Work Item Aging Chart (WAC)
Während CFD und CTS primär die Vergangenheit betrachten, fokussiert das Work Item Aging Chart die aktuelle Situation.
Es visualisiert:
- welche Elemente aktuell im System sind,
- wie alt diese Elemente sind,
- und wo möglicherweise Handlungsbedarf entsteht.
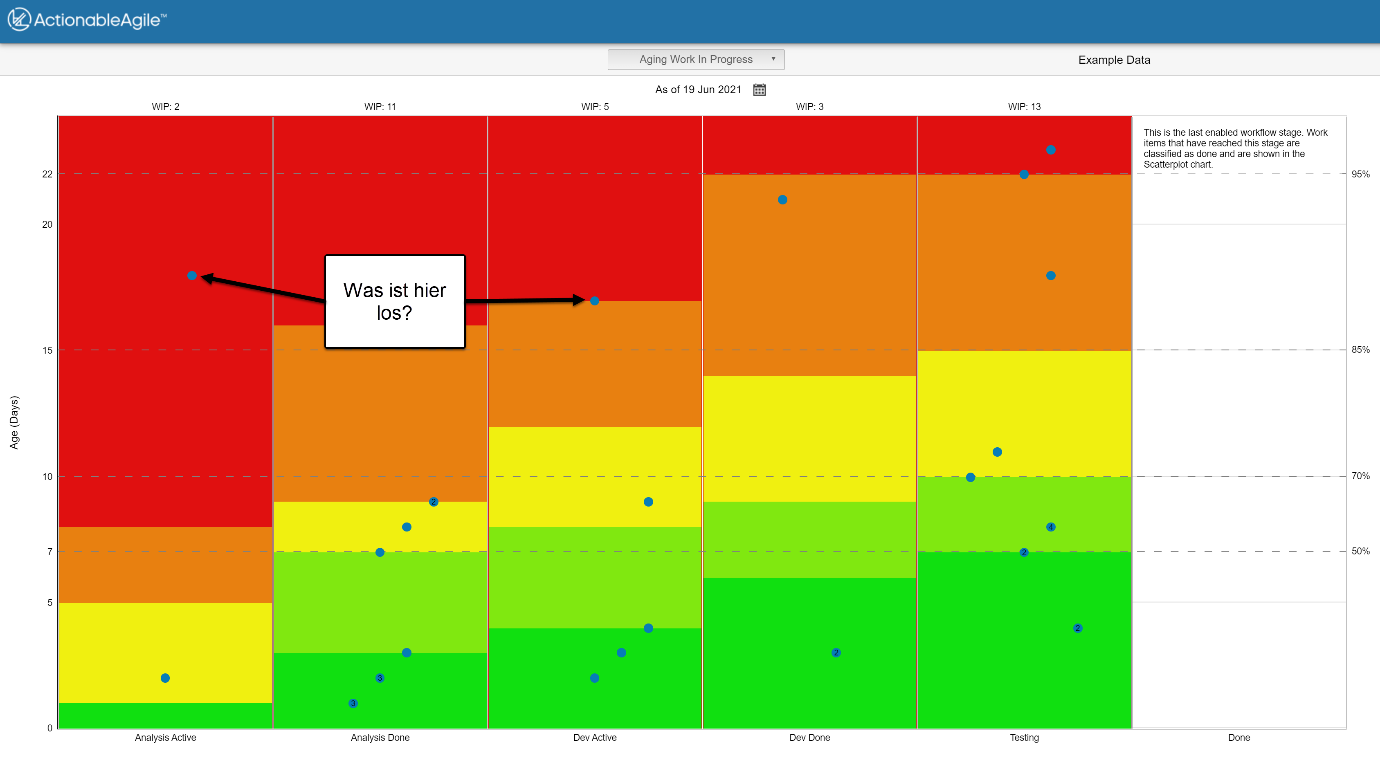
Abbildung 4 – Work Item Aging Chart
Gerade im Daily Scrum hilft diese Visualisierung Teams, die richtigen Fragen zu stellen und über die Dinge zu diskutieren, die die Stabilität des Systems am meisten gefährden.
Metriken manuell erheben
Viele Tools bieten heute automatische Ermittlung und Visualisierung von Flow-Metriken. Das ist praktisch. Gleichzeitig entsteht dadurch jedoch manchmal ein Problem:
Teams konsumieren Dashboards, ohne die zugrunde liegenden Zusammenhänge wirklich zu verstehen.
Dabei lassen sich die meisten dieser Metriken erstaunlich einfach manuell erheben. Selbst mit einem papierbasierten Board genügt oft:
- das Zählen von Elementen,
- und das Markieren von Tagen.
Dadurch entsteht häufig sogar ein besseres Verständnis für das tatsächliche Verhalten des Systems. Werkzeuge können unterstützen. Das Verständnis des Systems ersetzen sie jedoch nicht.
Flow-basierte Planung
Die vorgestellten Metriken lassen sich auch für Forecasts und Planung nutzen. Eine typische Frage lautet beispielsweise:
„Wie viel Arbeit können wir voraussichtlich im nächsten Sprint abschließen?“
Hier kann der durchschnittliche Throughput hilfreich sein. Wenn ein Team in den letzten Iterationen durchschnittlich 24 Elemente abgeschlossen hat, liegt die Erwartung nahe, dass eine ähnliche Größenordnung auch zukünftig realistisch ist – vorausgesetzt:
- die Kapazität bleibt ähnlich,
- die Elemente sind vergleichbar klein geschnitten,
- und der Flow bleibt stabil.
Eine weitere typische Frage lautet:
„Wann wird ein bestimmter Umfang vermutlich fertig?“
Auch hierfür lassen sich historische Throughput-Daten verwenden.
Monte-Carlo-Simulation
Eine besonders interessante Methode ist dabei die Monte-Carlo-Simulation. Dabei werden auf Basis historischer Daten Wahrscheinlichkeiten für bestimmte Fertigstellungstermine simuliert. Anstatt ein einzelnes fixes Datum zu nennen, entstehen verschiedene Wahrscheinlichkeiten.
Zum Beispiel:
- 70 Prozent Wahrscheinlichkeit bis zum 13. September
- 95 Prozent Wahrscheinlichkeit bis zum 25. September
Dadurch verändert sich die Kommunikation mit Stakeholdern erheblich. Denn plötzlich wird sichtbar: Komplexe Wissensarbeit ist grundsätzlich mit Unsicherheit verbunden.
Die entscheidende Frage lautet daher nicht: „Wann wird es exakt fertig?“
Sondern vielmehr: „Wie verlässlich soll die Prognose sein?“
Eine hundertprozentige Sicherheit wird dabei praktisch niemals erreichbar sein. Und genau das wird in klassischen Projektplänen häufig ignoriert.
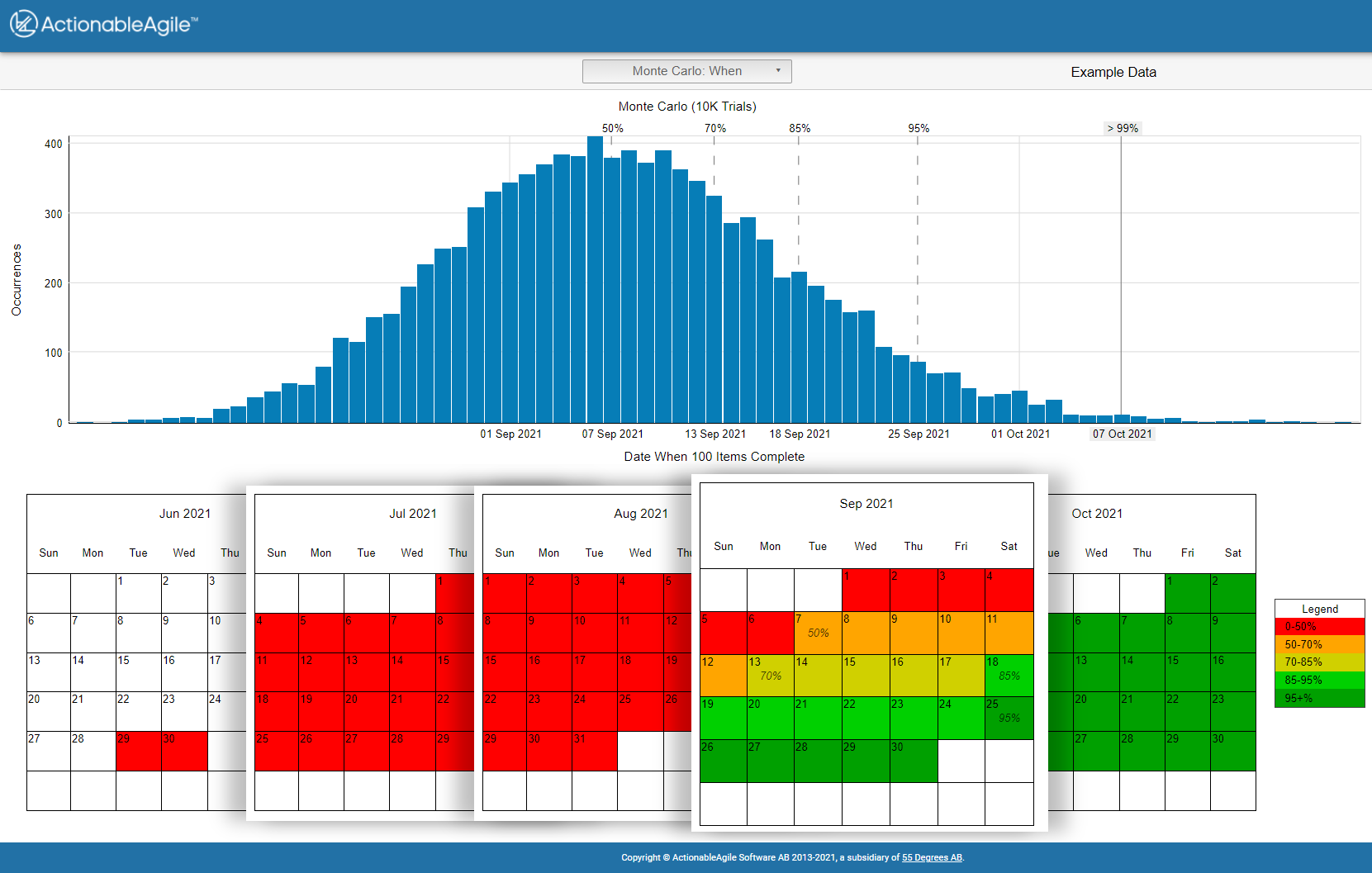
Abbildung 5 – Monte Carlo Simulation
Wer sich mehr mit der Monte-Carlo Simulation und den dahinterliegenden Berechnungen beschäftigen möchte, dem sei dieses englischsprachige Video empfohlen.
Prognosequalität entsteht aus Systemstabilität
Die Qualität solcher Forecasts hängt wiederum stark von der Stabilität des Systems ab.
Je geringer die Variabilität von:
- Cycle Time,
- Throughput,
- WIP,
- und Blocked Time,
umso stabiler werden typischerweise auch die Prognosen. Damit schließt sich der Kreis: Flow-Optimierung verbessert nicht nur Delivery. Sie verbessert auch die Vorhersagbarkeit.
Teammetriken vs. End-to-End-Flow
Eine wichtige Gefahr beim Umgang mit Metriken besteht darin, ausschließlich einzelne Teams zu betrachten. Denn ein Team kann hervorragende lokale Metriken besitzen und trotzdem schlechten End-to-End-Flow erzeugen.
Beispiele dafür sind:
- lange Wartezeiten zwischen Teams,
- Architekturabhängigkeiten,
- Freigabeprozesse,
- Security Gates,
- oder organisatorische Übergaben.
Gerade deshalb sollten Flow-Metriken möglichst nicht isoliert auf einzelne Teams reduziert werden. Denn der eigentliche Flow entsteht meist über das Gesamtsystem hinweg
Moderne Delivery-Metriken
Im Kontext von DevOps und Continuous Delivery haben sich darüber hinaus weitere technische Metriken etabliert. Besonders bekannt sind die sogenannten DORA-Metriken:
- Deployment Frequency
- Lead Time for Changes
- Mean Time to Restore (MTTR)
- Change Failure Rate
Diese Metriken betrachten stärker die technische Delivery-Fähigkeit eines Systems. Auch sie liefern wertvolle Hinweise darauf, wie gut organisatorischer und technischer Flow zusammenspielen. Wer tiefer in diese Themen einsteigen möchte, findet dazu weitere Gedanken in meinem separaten Artikel zu den drei Wegen von DevOps.
Fazit
Bereits wenige, vergleichsweise einfache Flow-Metriken können enorme Transparenz über das Verhalten eines Systems schaffen.
Sie helfen Teams dabei:
- Engpässe sichtbar zu machen,
- Risiken früher zu erkennen,
- bessere Forecasts zu erstellen,
- und systemische Verbesserungen gezielter anzugehen.
Dabei liegt die eigentliche Stärke dieser Metriken nicht darin, perfekte Zahlen zu liefern. Ihr Wert entsteht vielmehr dadurch, dass sie die richtigen Diskussionen anstoßen. Flow-Metriken sind deshalb keine Werkzeuge zur Kontrolle einzelner Personen oder Teams, sondern Werkzeuge zum Lernen über Systeme.
Natürlich kommt es dabei entscheidend darauf an, wie diese Metriken genutzt werden. Sobald sie zu Zielvorgaben werden, entstehen schnell Fehlanreize. Werden sie dagegen als Informationsquelle verstanden, können sie enorme Verbesserungen ermöglichen.Und vielleicht ist genau das die wichtigste Erkenntnis:
Metriken verbessern keine Systeme.
Menschen verbessern Systeme!
Metriken helfen lediglich dabei, früher zu erkennen, worüber gesprochen werden sollte.